Welcome to Part IV of the series. If this is your first encounter with this collection of articles, it might be worth having a read through the first three parts. All of which are relatively short – Part I, Part II, Part III.
Never use language keywords as object keys
Every time I see an object key called return, function or def I cringe. If you’ve ever encountered this, you probably already know why. Indexing such an object in any programming language is messy. You can’t just use the dot notation and indexing programatically is a beast of its own, escaping the string is the shortest solution, however you don’t want to have different way you index objects across your codebase . To keep things consistent you might end up editing your entire code because of a single object. It’s a terrible practice, please don’t do it.
Distributed systems optimistic assumptions are always wrong
I was an optimist when I started when it came to distributed systems. After all, up to this point I’ve never seen google.com or amazon.com being unavailable. I was very wrong. Peter Deutsch (Sun Microsystems legend) has phrased the most common fallacies of distributed systems brilliantly, so I’ll put his comment here:
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn’t change
- There is one administrator
- The network is homogeneous
Don’t forget these assumptions are always wrong.
Humans are terrible at scale perception
Our ancestors rarely had to work in the scale of billions, if ever. We haven’t changed that much over the years, so our perception of scale is not great. Thinking of something that takes 120ms as fast enough, is actually ‘centuries’ when it comes to database writing. This a very old image that’s been circling around the internet for ages. It’s a list of common computer latency numbers, scaled for easier comparison.
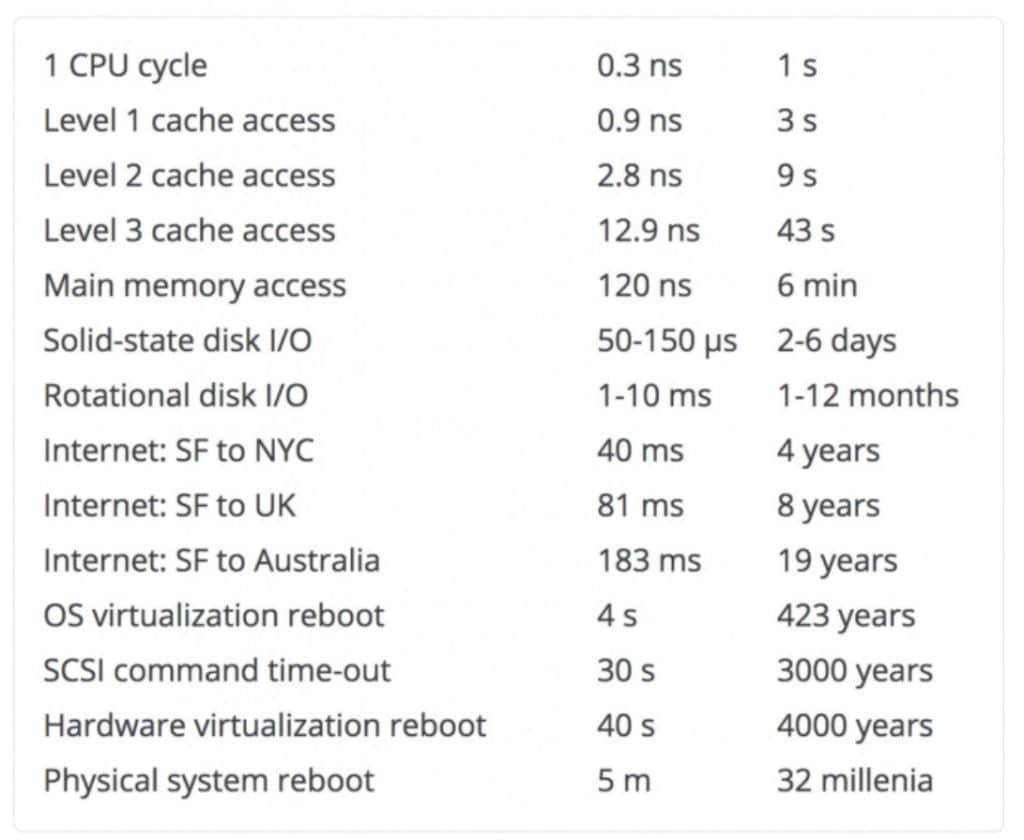
I always think of this chart when I write code, especially if the operation will be done at least million times a day, you should too. Implementing caching in memory compared to fetching every time, might be 20 minutes more coding, but the saved operational time will be 10-fold.
Functionality over User Experience
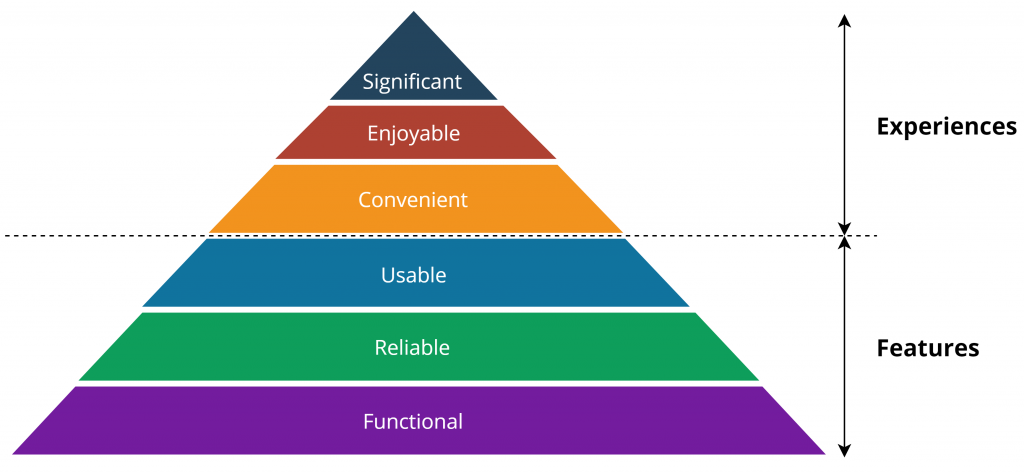
This one is quite obvious, if your product doesn’t work, doesn’t matter if it has the prettiest user interface. You can get away with non-user friendly product that works, but not vice versa. However, once you have the functionality done, don’t forget to go back and do the user experience right, this is more commonly known as the UX Design Pyramid. Don’t fall in the trap, that as long as it works, it shouldn’t be modified.
The creative process is messy and that’s OK
Even with all the tooling we have in 2019, the software engineering process is still messy. Inconsistent environments, stuff working under specific conditions in some places, but not others make building software still messy. The more moving parts the system has, the more complicated the build and testing process is. That’s OK. Really! If you go to an artist’s studio, it’s a mess for the exact same reason – experimentation. Chances of getting it right on the first attempt are very slim, as you get more experienced, you still go through the same idea validation process, just faster. Don’t seek the illusive perfect setup, in order to get to work, you will never achieve it.
A deleted line of code in a top level system is a line added downstream
I don’t have scientific evidence to prove this statement, but the majority of people working long enough with distributed systems will agree. If a subsystem takes care of a new parameter and you don’t have to validate it anymore, the validation logic just got moved (you would hope), it didn’t vanish. There are probably exceptions to this rule, I just can’t think of any right now.
You might have picked the wrong language
As technology evolves, so does the tooling geared towards solving the new problems. Chances are if you are a master of C++, doesn’t mean C++ is the panacea for anything someone throws at you. A perfect example – Have you worked with JSON and web services in C++? It’s plain terrible. Because you need to know your object schema in advance to know how to deserialize/serialize the object, edit, etc. If you work with schemaless data store, you are in a for a ride. Not impossible, just plain time consuming. Compare this to JavaScript or Python, merging two dictionaries is a one-liner. Their performance is nearly incomparable, but if you catch yourself spending too much time on a simple task in the language of your choice, you probably picked the wrong tool. The best language for something today, might not be as suitable tomorrow. Acknowledge it fast and switch to the right one.
The software engineering approach is a spectrum
On one side you have “I’ll do it by myself”, where you struggle and take longer, but learn more and things start to click faster for the entire engineering process. On the other end you have “This guy already knows how to do it, I’ll ask him directly” where you gain knowledge from senior people, who can explain why things are this way. Neither is absolutely right or wrong. Sometimes one is better than the other, because of deadlines, very limited knowledge, etc. But try to keep balance. The middle would be something like – trying solving it yourself and getting a pointer from a senior on to correct your approach or set the right course for redesign.
Code quality is more important than you think
Complex system engineering is quite an interesting job. However, you can’t store the entire system’s logic in your short-term memory. I don’t remember code I’ve written more than 6 months ago. I just don’t. I also don’t want to. If I wrote it well, 5 minutes of reading should bring me up to speed. Rather than tracing code across 50 files and and tracking every change someone has done on it through the months. Beware of developers, who write code, like they won’t support it in 2 years time. Code quality, might be taxing during the code review process, but will save you and your team time, the next time you need to check how something works or needs to be fixed. Be proud of what you write. Your current code will be someone’s legacy codebase tomorrow.

Until next time! Happy Coding!



0 Comments