Welcome to Part III of the coder to software engineer series. You might be interested in reading the first two posts – Part I and Part II.
Optimization is mostly useless
You would meet a lot of perfectionist in the software engineering profession. They like to optimize their code, like the product is going to have Facebook’s or Google’s usage. It rarely is needed and some times even leads to over-engineering. Even large companies have to redesign as their product usage increases.
One example is Twitter’s handling of tweets on timelines – Video here by Raffi Krikorian. Optimization is useful up to a point. You should still develop and design correctly – reducing amount of database hits, setting up archiving mechanisms for data storage, focus on fault-tolerance and so on. However, eventually every piece of software reaches a point of diminishing returns, where the costs exceeds the benefits. Perfection is the enemy of progress.
The reality often is and I’m sorry to tell you, your product will most likely not have Facebook or Google level usage. So that cost is often unjustified.
If your product does really reach massive usage, it will probably take at least 6-7 years at minimum and by that point there will be newer technologies, you will have better understanding of usage patterns and useful features and will be much better off rewriting it, possibly in a new more suitable language.
Let’s take a Fortran codebase as an example. It’s still quite pervasive in many large corporations. In 2019, if you need to maintain such codebase, would you really spend
time optimizing it further, rather than just switch to a cloud technology or write it in a very readable Python. Would you really appreciate the extra optimization effort the person put in the 1980s shaving off that 0.01ms runtime, when your usage is so much bigger now and no level of optimization of that code would save you today.
Technology changes, usage changes, you need to adapt your tools and your codebase alongside it as well.
Time Investment in Programming
Personally, this is the one I struggle the most with. How do you know what to invest your time learning? Jumping from a JavaScript framework to another doesn’t give you much deep understanding, so you need just a single foundational one, and you will be able to learn all derivatives quite easily. You get more technologies, languages and frameworks produced every year, as hardware and software get more specialized.
I like to break them down into 3 categories:
Fundamental – Technologies that cover the basics of computing and not going anywhere.
You might do Python, but you need to know Pointers and Memory allocation and what Garbage Collection does for you.
Examples – C, C++, SQL, JavaScript
Trendy – What new companies are using, but future relevance is uncertain.
This is the so called, flavour of the year, you need it to be relevant in the today’s coding world. But might not be used in 10 years time.
Examples – AngularJS, ReactJS, Blockchain
The way forward – The next generation of world-shaping technologies
The technologies that are just gathering steam and will become mandatory in the future
Examples – The Cloud Infrastructure (AWS, Azure, GCP), Serverless, Machine Learning, Natural Language Processing
So every new technology someone throws at me, I try to evaluate in which category it fits and how likely it is to move in either of the 3. You should have the most in the “Trendy” section, otherwise you are most likely classifying them wrong.
Here is a good place to also mention the Gartner Hype Cycle. It hypothesizes the stage every technological development goes through.
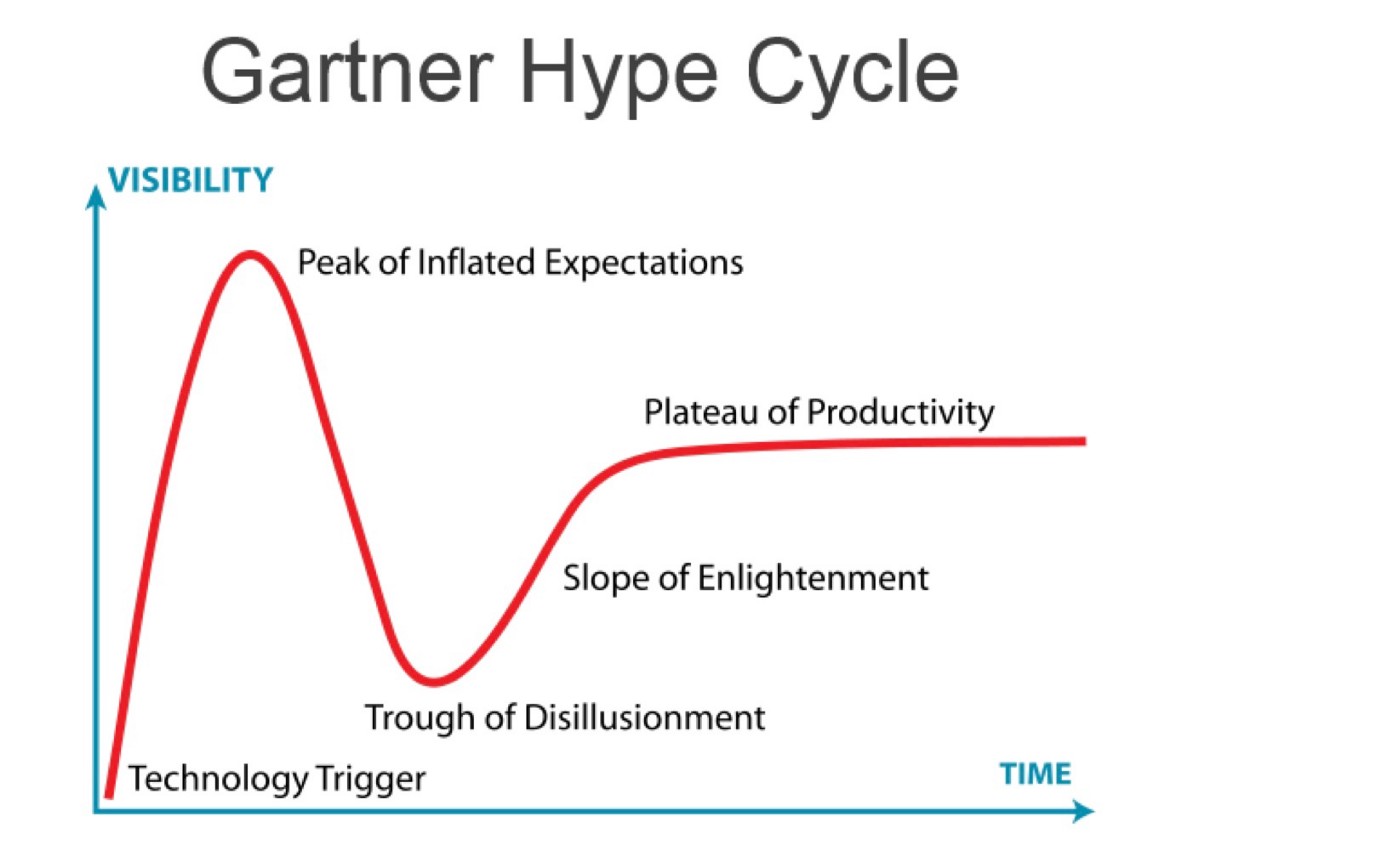
It breaks the cycle into 5 phases:
Innovation Trigger – Innovation, eg. faster wireless internet enables Internet of Things, kicks off POC and MVP ideas.
Peak of Inflated Expectations – Media hype ensues, the “next big thing” is coming soon.
Trough of Disillusionment – Media hype is gone, initial iterations fail to deliver on the inflated expectations. People start to lose interest.
Slope of Enlightment – Second and third iteration actually start to deliver and people’s expectations are adjusted. Pivoting around the technology might happen.
Plateau of Productivity – Mainstream adoption has started. Technology usability is paying off.
The above chart should be your reference point at which stage the technology you are evaluating is in and allow you to classify better.
Transparent system doesn’t mean more logs
Sure, logs are great for troubleshooting. In distributed systems development, you don’t have much else to rely on. Especially, if you don’t know what downstream services are doing. Striking the right balance is what counts. Too many logs, and you will drown in the noise of repeated useless information, too little and you might as well be guessing what happened inbetween two events. Transparency is something much more – it’s predictability. Even if your system is going to fail after certain sequence of events, it should fail the same way every time. Distributed system developers should always assume hardware fault cases. You should minimize caring about other systems’ error differentiation. They return an error, you should fail gracefully the same way every time. Your error reporting should be meaningful. Use error codes, error levels, whatever makes sense that allows you to save time going forward. The cost of opaque systems is too high for any company in the long-term when a developer spends 1 day trying to figure out what failed and where and why, rather than improve stability or add new features.

Address breaking changes as soon as they arise
Programming languages and frameworks evolve. Sometimes, they need to make breaking changes to prepare for the future. That’s life, you accept it. This is particularly true for front-end these years (ReactJS and AngularJS I’m looking at you). Do not be that person who waits for the last moment just before rollout to resolve them.
Here’s why:
1 breaking change, you know where to edit and how it propagates – you are focused and editing is clear. Pull Request is readable.
2 breaking changes, you edit two totally unrelated files and your edits interconnectedness is murky. Pull Request is somewhat readable.
>3 breaking changes, the moment anything breaks, you are lost which of the 3 things you fixed caused it and which of all edits was the culprit. Pull Request logic is all over the place. You might have been fine with 5, but you are playing with fire. Additionally, when you address them as they arise, it’s less annoying and faster to fix. The cost later will be much less. Have a rota in your team, if need be.
The too afraid of releasing anti-pattern
I’m going to name this the lockdown anti-pattern. How do you get yourself in it? If you don’t release small changes frequently, but have one big release. If something breaks in 1 of the features added, you have to roll back and lose the other 5, yet they were perfectly fine. Then you might want to release only these 5, as the fix will take a few days. It spirals into a mess. Due to scare of breaking things going forward, people will become reluctant to rollout themselves and take on the risk, thus more features accumulating in the meantime and releases get bigger and bigger and you end up in the vicious cycle. How do you get out of it? Make releasing a habit, not a special event. However, getting out of this anti-pattern is easy, but getting in it is a symptom. How did you end up here in a first place? Too many big releases too fast? Untested code? Cut corners to meet a deadline? This is what needs to be investigated by your team.

The last 10% are always the hardest
I suppose this goes for most things in life. After you’ve finished writing your business logic, now you need to write new tests, fix some old ones. Then you need to rebase your branch, as you’ve been working on it for 2 months. There are some merge conflicts you are unsure about and need to clear. Wait, turns out you’ve picked up a newer version of framework XYZ, that has introduced breaking changes, you need to fix that first. You get the point. The amount of things between the phases “code complete” and “rolled out” is large, it’s frequently underestimated (myself included) as every proud developer wants to get their feature out in the real world.
Build the monolith first, then break it into pieces
Nowadays, everything is microservices. So people start building many tiny pieces without having a clear vision on how to assemble them later. Everyone knows having a monolithic codebase is bad, distributed one is good. But maybe you should start with a monolith, shape it. It will be clearer on which responsibilities should be delegated into what microservices. It avoids the Pareto principle – having 1 “microservice” that has 80% of the business logic and 10 others that have the remaining 20%. In other words, it’s easier to have a picture and slice it into puzzle pieces you can assemble back together, than cut out puzzle pieces individually and hope they fit afterwards. This will save you headaches with obsolete schema types, calls and others.
Elusiveness of tech debt
Tech debt is everything a coder will need to pay back later – an implementation shortcut they’ve taken, not encapsulating logic in a single place (spaghetti code), over or under-engineering a feature that will prevent it from being extensible, etc. The thing with software design and development is, you never know if you are backing yourself into a corner. Something that makes perfect sense right now, might look like a terrible implementation in 5 years time. This is where experience is invaluable. The rule is simple. Keep your implementation open as much as possible, up to a point without adding cost to the development of the feature. As in 3 months, things might take a 180 degree turn. I see this constantly – Developers are always quick to judge and bash on new code they see. As they would have done it better in a different way. Sure, but they weren’t in the circumstances the original developer was in that required implementing it this way. Tech debt is not as evident as people think. You can notice “code smells” as a harbinger to tech debt, but can never be 100% sure.

I hope you’ve enjoyed the post. If you’ve found it useful and think others might too, share away!



0 Comments