In this post we’ll explore what is GraphQL and when it makes sense to use it. We’ll map an existing SQL database (SQLite) with an Object Relational Mapping (ORM) system – SQLAlchemy in Python, and finally unify both concepts by using the ORM bindings inside GraphQL queries and start up the web server with Flask. If you want to get the final code, it’s hosted on GitHub. Give it a star, if you found it useful.
GraphQL vs REST
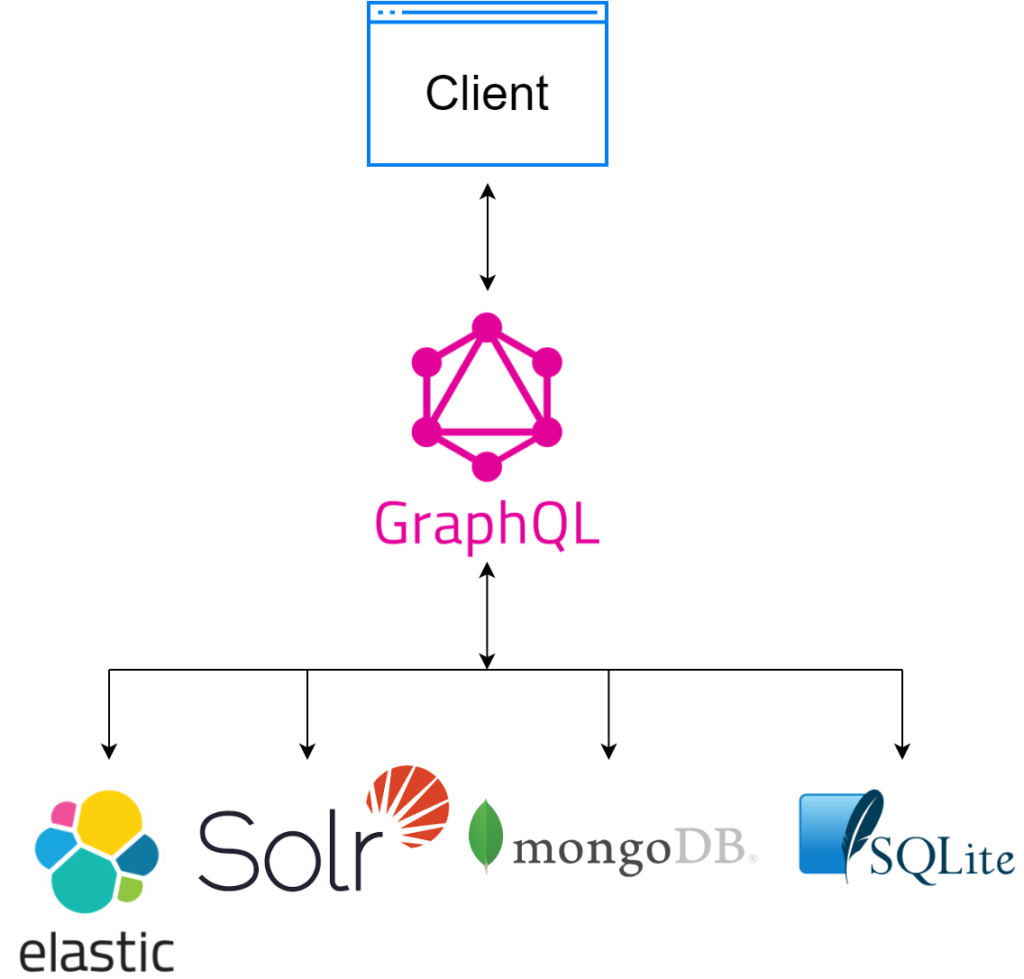
GraphQL is not a replacement for REST, it’s more of an extension, both use the HTTP protocol. It has quite a few benefits:
- Fetch from multiple endpoints with one request
- Instead of calling /student/<id>/grades, /student/<id>/classes and collect data from multiple sync requests, you can query at once and reduce server round trips
- Control over returned response structure
- Fetch only the needed data, no under/over fetching, offering bandwidth savings. You can get only the data you need and are not bound to fixed responses as with REST
- Strongly-typed schema
- Great to know how to query, leans towards self-documenting
- Has the overhead of verifying types
- Abstraction of multiple data stores
- The strongest argument in favour of GraphQL is to act as a single endpoint across multiple data stores, offering consistent fetch mechanism on client side and making it data store agnostic
- Great for graph relationship representation
- Since querying nested arguments is easier, it makes graph relational data much easier to fetch
- Dataloaders for batching queries
- It offers ability to aggregate queries in an ‘execution frame’ and reduce load on the backend data store. You can read more on the mechanics here
- Subscriptions
- Offers both sync and async models in a single API, where multiple clients can listen for events with minimal setup
It’s not all perfect, thus some considerations:
- Versioning
- Unlike REST, where you can do /v1/<call name> and version this way. There is no explicit versioning, so you can just as easily remove and add fields. Great for fast schema iteration, problematic for field deprecation
- Fetching too much
- You can unintentionally fetch too much, you need to have some form of returned data limiter, which can become complicated if you want a consistent approach across multiple data stores
- Caching
- Because of great request/response flexibility, it becomes harder to cache due to the high variability. Oftentimes, the benefits gained in ease of use with the freeform interface are lost in performance due to lower cache hit rates
- Error handling
- It doesn’t have explicit REST-like status codes, can recreate manually. But error handling becomes tedious since you need to parse the response all the time.
- Most of these features can be recreated in REST with arguments to a POST request
- A little messier, but depending on the end result you are going for, it could be the easier route
- Gets complicated very fast
- It’s a separate universe compared to REST with Types, Unions, etc, not suitable for small projects
Getting Started
Since we are going to use SQLite, for the SQL database and Python 3 with PIP. We can install them via sudo apt-get install sqlite python3 python3-pip for debian-based distributions or sudo yum install sqlite python3 python3-pip for RHEL ones. I’ve done all the setup on a Ubuntu WSL2 distribution, so I can confirm that it works fine on WSL in Windows. Once we have those up and running, we’ll need to install a few python packages that we’ll use to setup a web server (Flask) and have cleaner bindings between GraphQL and SQLAlchemy (Graphene, Graphene_SQLAlchemy), so run python3 -m pip install flask flask_graphql sqlalchemy graphene graphene_sqlalchemy, if you don’t have admin privileges for the machine, append --user to the command.
A small note on folder layout, as per the GitHub repo, in order to not mix SQLAlchemy bits with GraphQL one and confuse you what belongs where, I’ve put all GraphQL-related files in a single folder.
Setting up the SQLite database
I’ve created a small sample school database with a few records, with the below relationships:
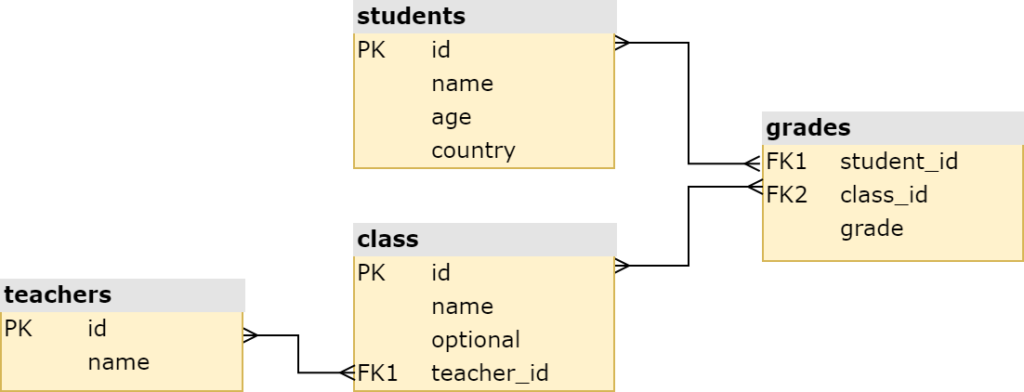
The primary design choice was to have a few tables with primary keys and some foreign key relationships, to make the example closer to reality. You can either directly download the database from here, or recreate the SQLite database by running:
sqlite3 schooldb.sqlite3 and when you are presented with the SQLite prompt paste the contents from this file, press Enter and then press Ctrl + D to exit.
SQL Table Models
We’ll start with the table definitions. We import the data types from the SQLAlchemy module. On their website the list of basic types is quite extensive. Since you now know the table columns from above, we are replicating them manually below. One interesting piece is defining a relationship, which I’ve done here for Teachers and Classes. This is used for defining logical relationship, so when I fetch a teacher object, they will have an list called classes list, to address the case where one teacher can teach multiple classes. You can define cascade relationship, for example when deleting a teacher record to delete all class records respectively and vice-versa. This is where the power of object relational mapping comes into play. Chances are your SQL database already supports these features, but this adds an extra layer of safety when it comes to deletion queries. In the below screenshot, you can see how I load the earlier created school database, then initialize a declarative_base(), meaning I will define the tables manually. SQLAlchemy also offers automapper, which should be good enough for basic tables, but can’t confirm on how well it works on complicated databases.
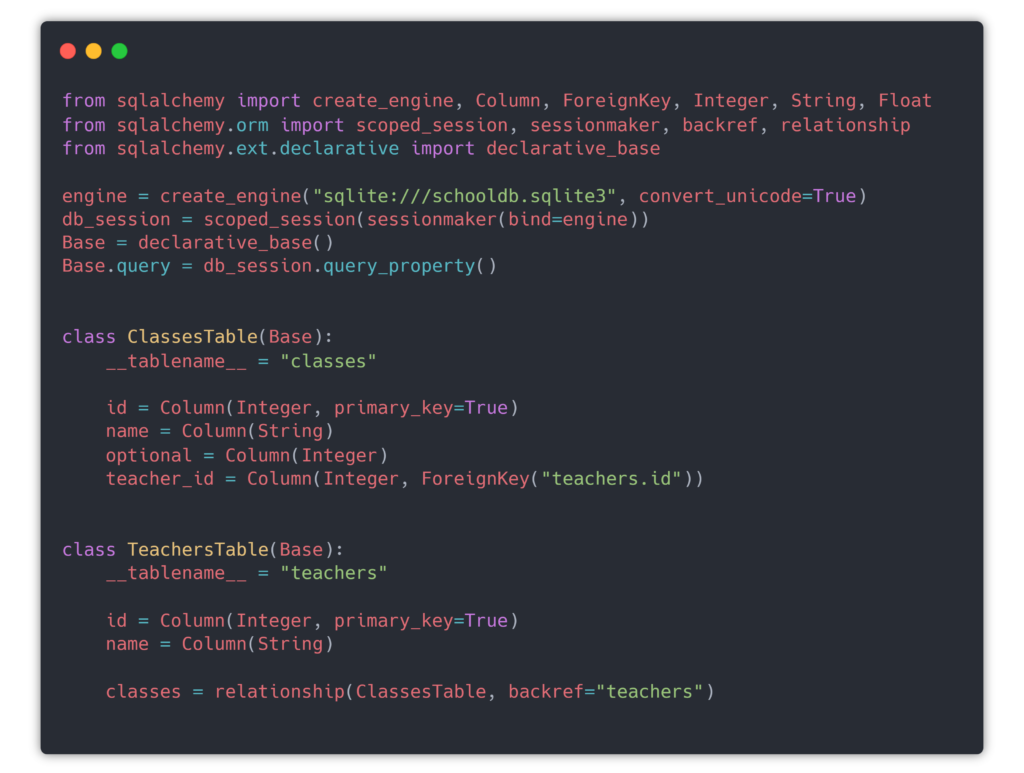
The no primary key issue
The SQLAlchemy no primary key error is quite popular. SQLAlchemy always needs a primary key in a table, even if it doesn’t have such. The reason is, you always need some kind of unique row identifier for deletion purposes. In our example, I’ve deliberately created the grades table, which has this problem, so we can work around it, following the suggestions from here and here.
GraphQL types from Table Models
Define the types where inside the class Meta, you pass the earlier defined table definitions. The magic here is actually done by SQLAlchemyObjectType. The fields classes below are needed only for the editing method called mutation. If you are only going to allow read-only, you can skip the AddStudentFields and StudentFields classes.
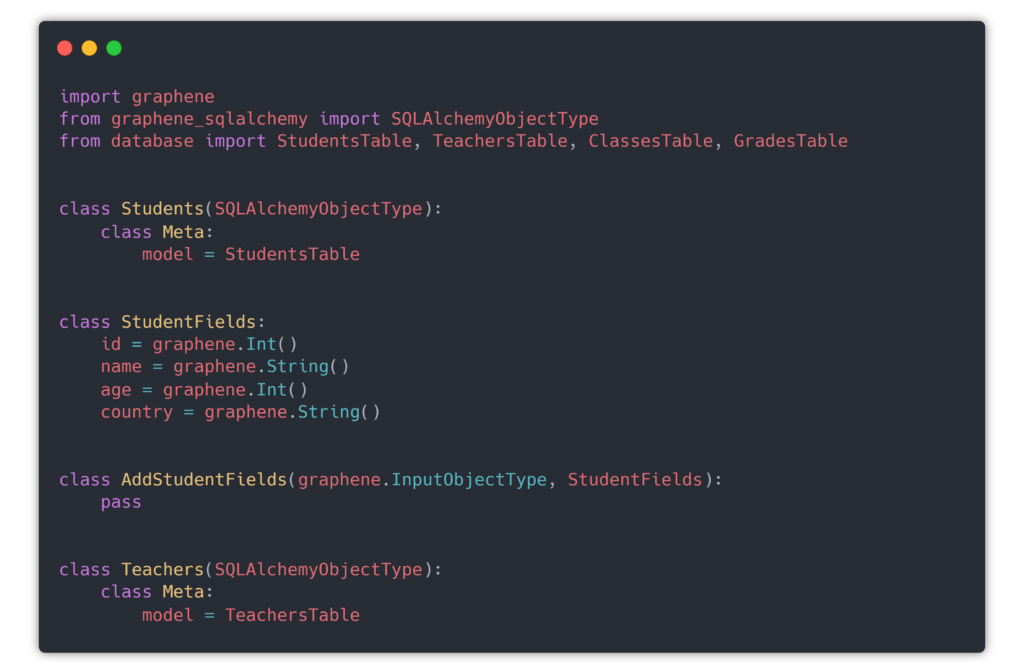
So far we have the type definitions on database side and on query side, so the next step is to query the database and return query types.
Querying Database and returning Query Types
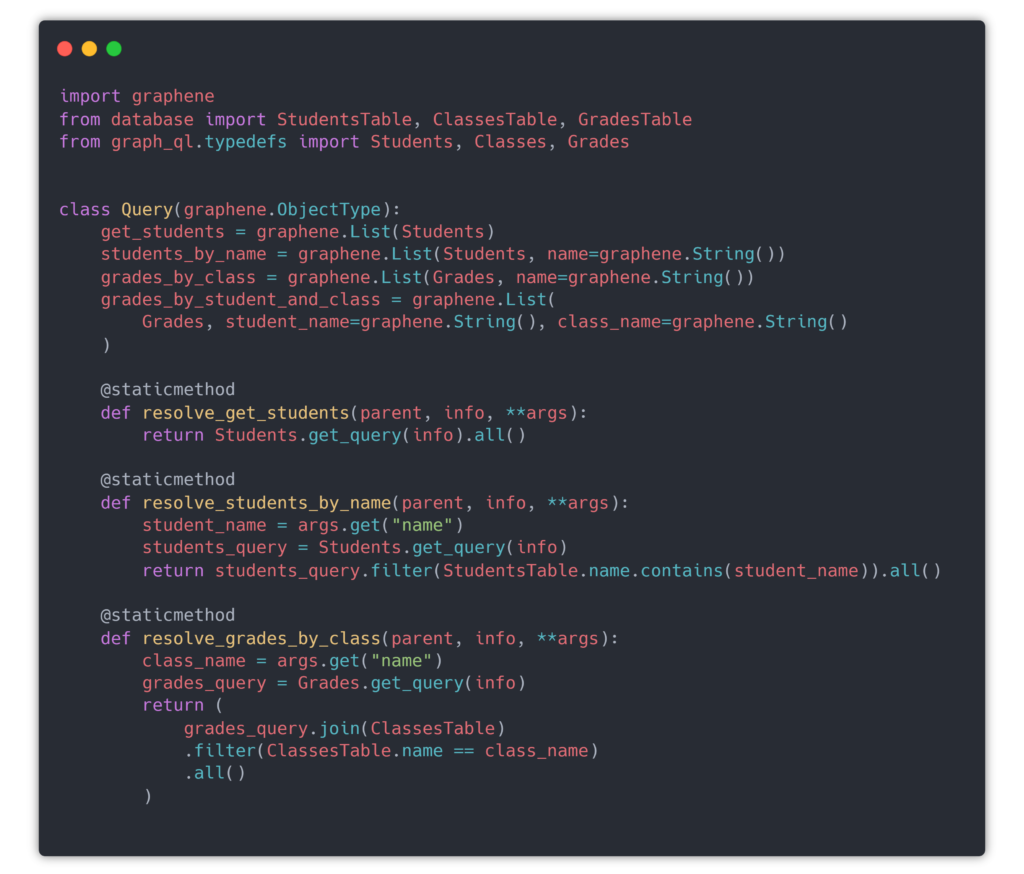
the most essential part is when adding your request types at the top, the actual resolve functions to be of the style resolve_<request_name> so the data is picked by the Default Resolver, more details on this you can read here. The argument types are passed as is and you can directly put them in the filter method for the SQLAlchemy object. It’s in the above screenshot where the magic happens. You query in JSON format SQL database. You still need to define how the database search is actually done.
Mutation queries
The UPDATE/INSERT queries are represented with the mutation keyword before the curly brace that starts the query.
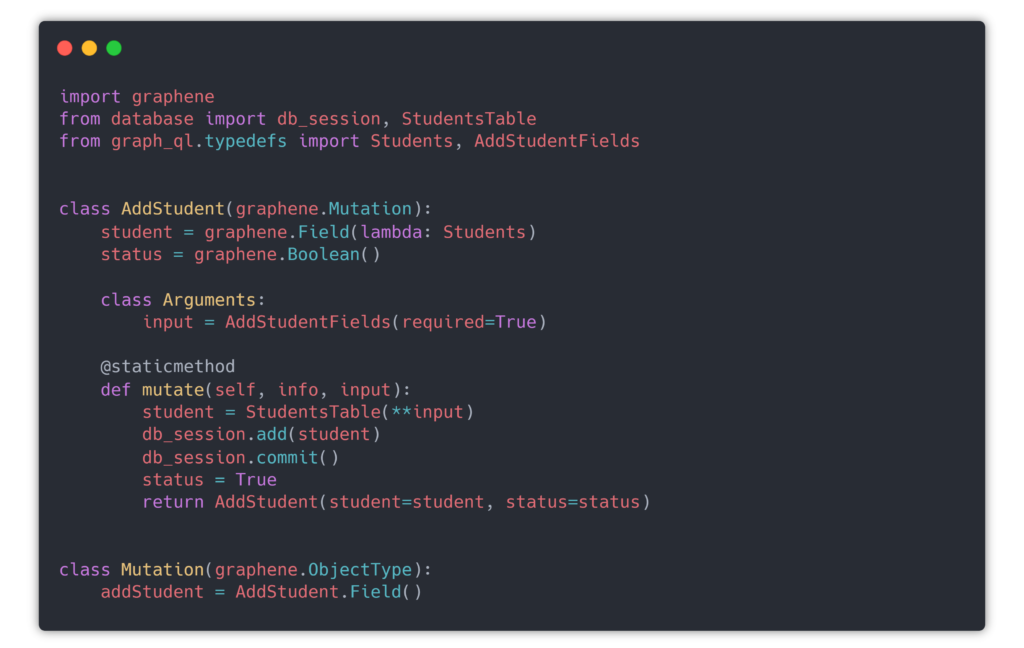
The definition is similar to the read queries, since we defined the StudentFields we directly pass them as to what to parse and how to store in the database respectively. No magic here, just more mappings. Once done, you can return an object of what you’ve added, I like to add a status, in case it fails, similar to an HTTP 200 response, above, I return just True, but you can do .rollback() for example if your SQL transaction failed and so on.
Hosting the GraphiQL with Flask
If you’ve worked with Flask before, there isn’t anything particularly different setup-wise about it. Since there’s a module that makes hosting the interactive query console a one-liner. Import the GraphQLView and add an endpoint to the Flask application. This will host the GraphQL endpoint, but until you set graphiql to True, you won’t get a UI.
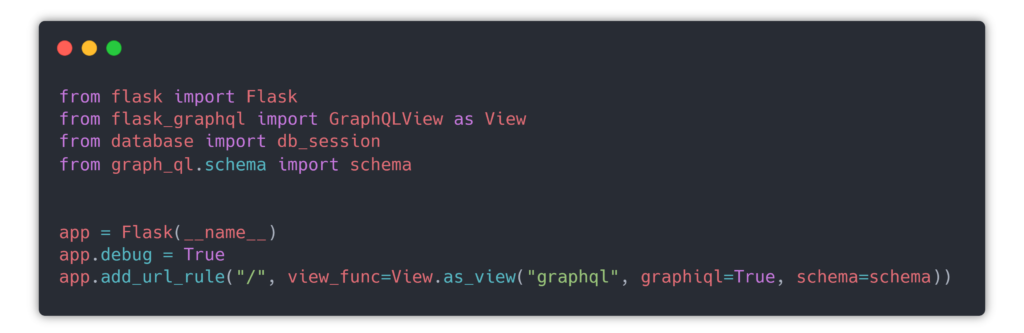
If this worked correctly, you should be able to reach http://localhost:5000 and get the below view:
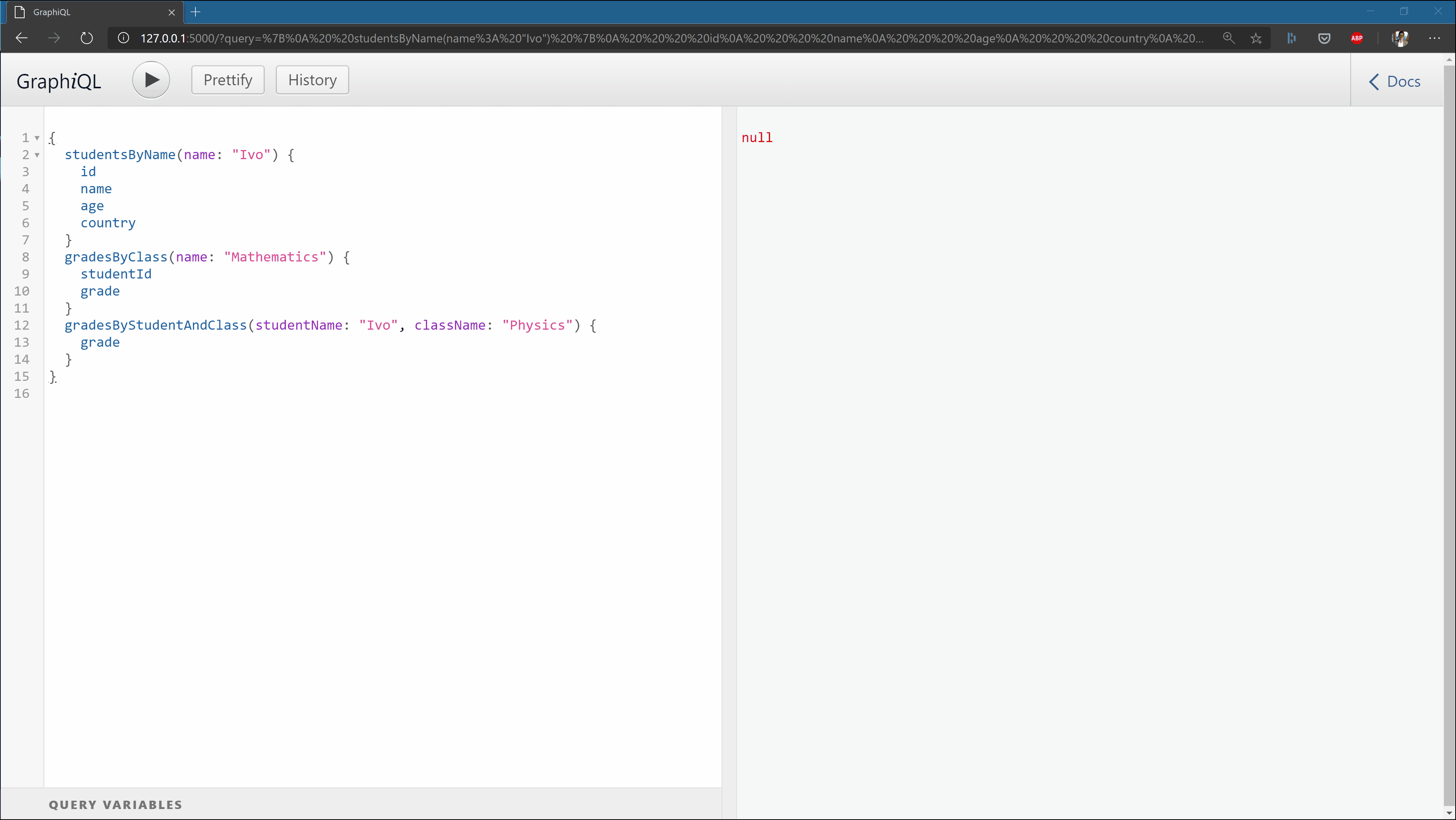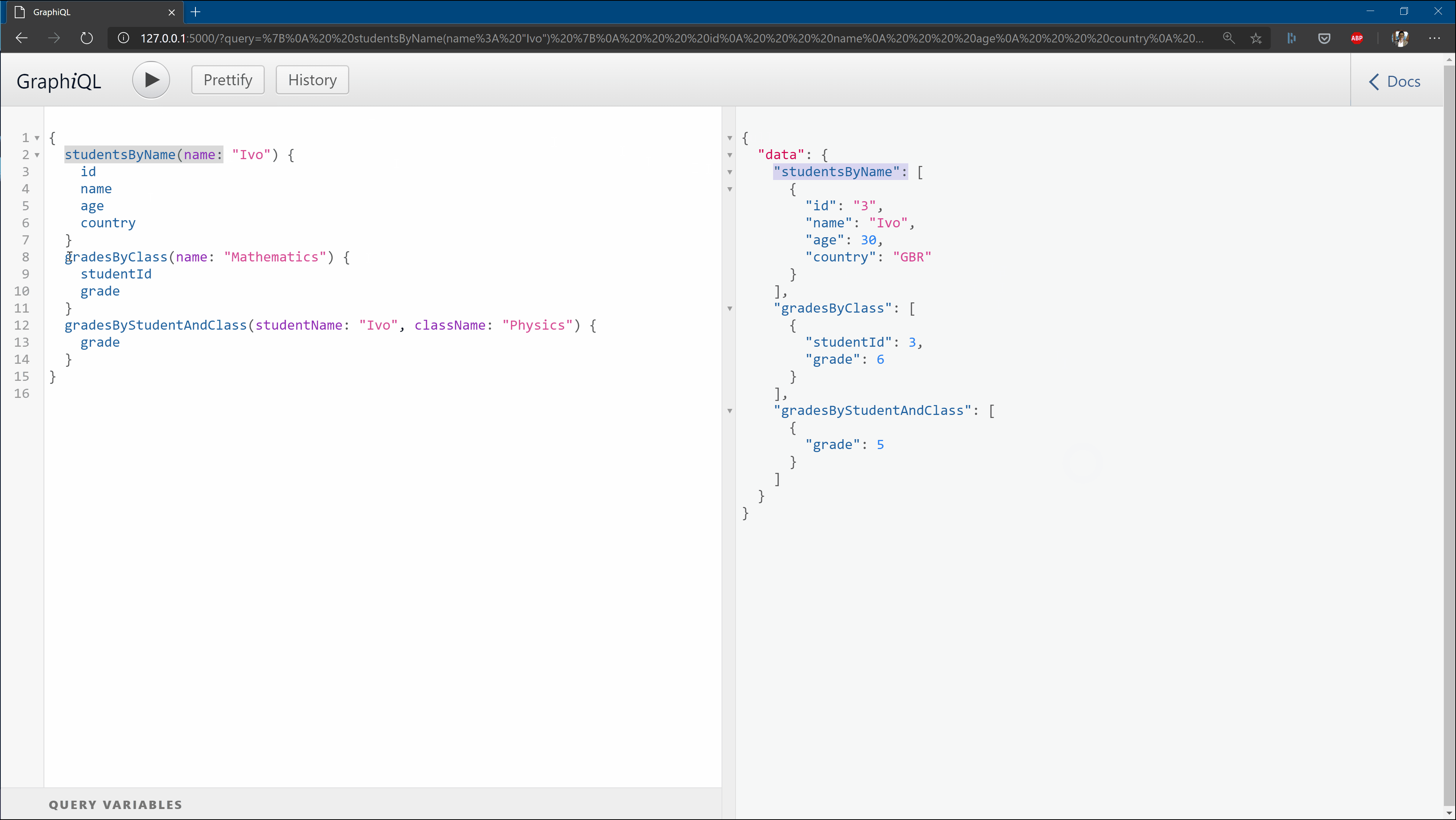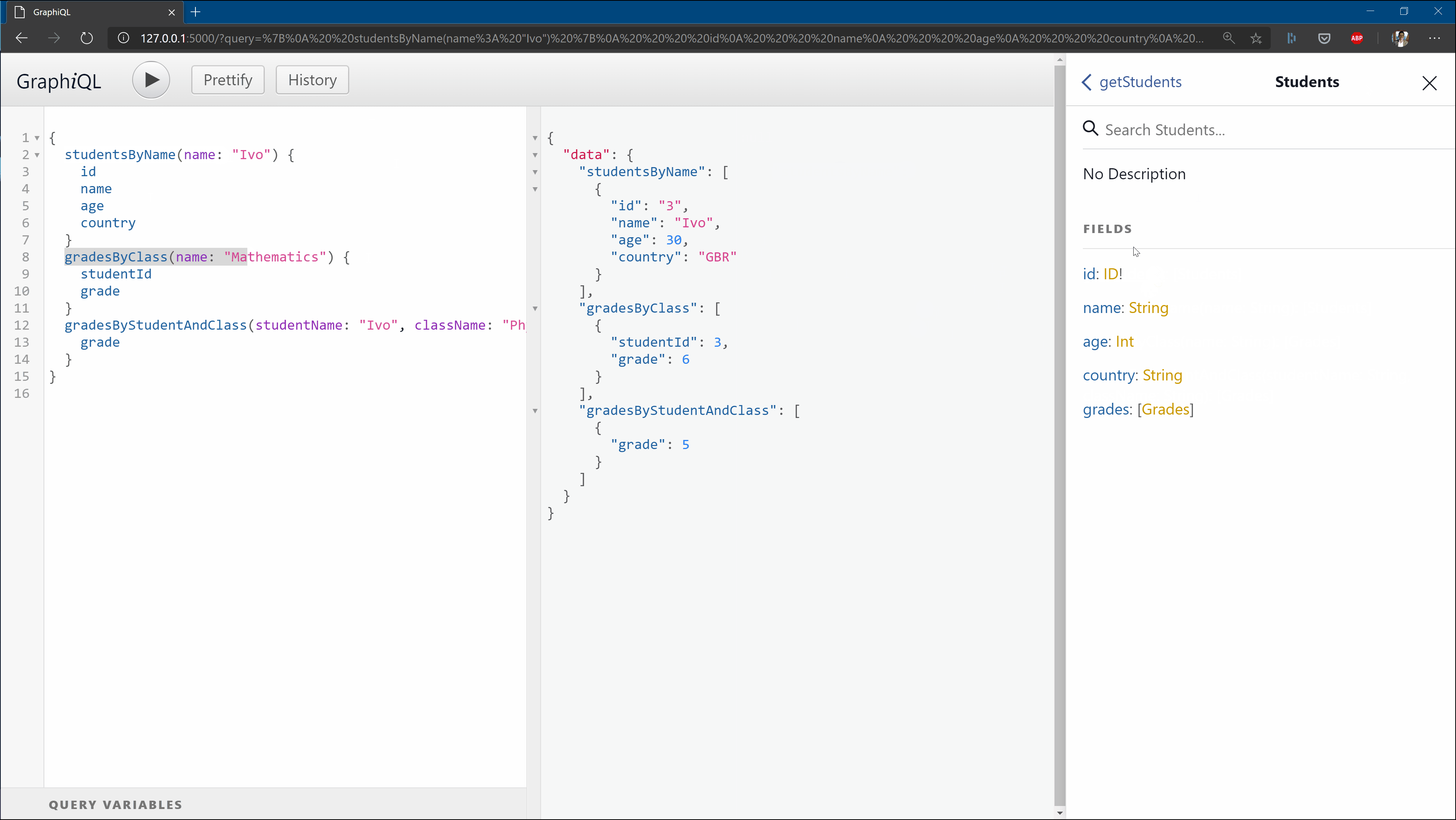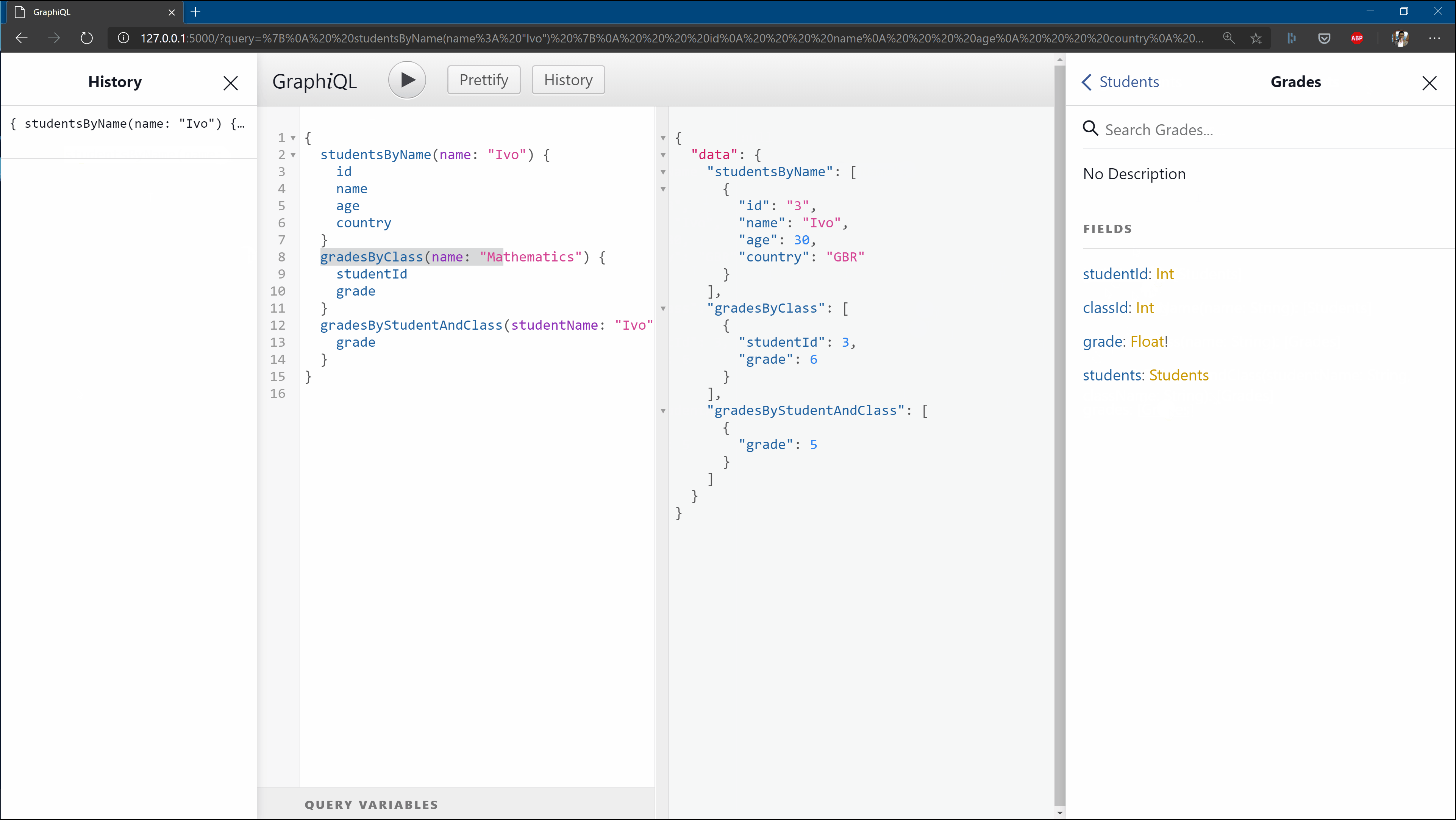
In the repo with all files, I’ve added a text file with sample queries you can try out as soon as you spawn the server locally.
I hope you’ve found this tutorial useful. Share with others, who you’ve always wanted to do the jump from SQL to GraphQL. Until next time!



0 Comments