Introduction to Apache Kafka

- High-throughput low-latency message broker for real-time data feeds
- Cross-platform
- Available libraries for all modern languages
- Written in Scala and Java
Performance
Scalability
- Infinite horizontal scalability
- Thousands of brokers
- Trillions of messages
- Hundreds of thousands of partitions
- Elastic storage and processing
- Extremely fast (2ms+)
- 15x faster than RabbitMQ
- 2 million writes per second*



High Availability

- Replayable data streams stored in a distributed fashion across an entire cluster
- Support for multiple availability zones across multiple geographic regions
- Started in LinkedIn in 2010 by
- Jay Kreps, Neha Narkhede & Jun Rao
- Open sourced in 2011
- Confluent main company behind the project
- Name was inspired by Franz Kafka
Brief History

What is Apache Kafka
Overview of Kafka Architecture

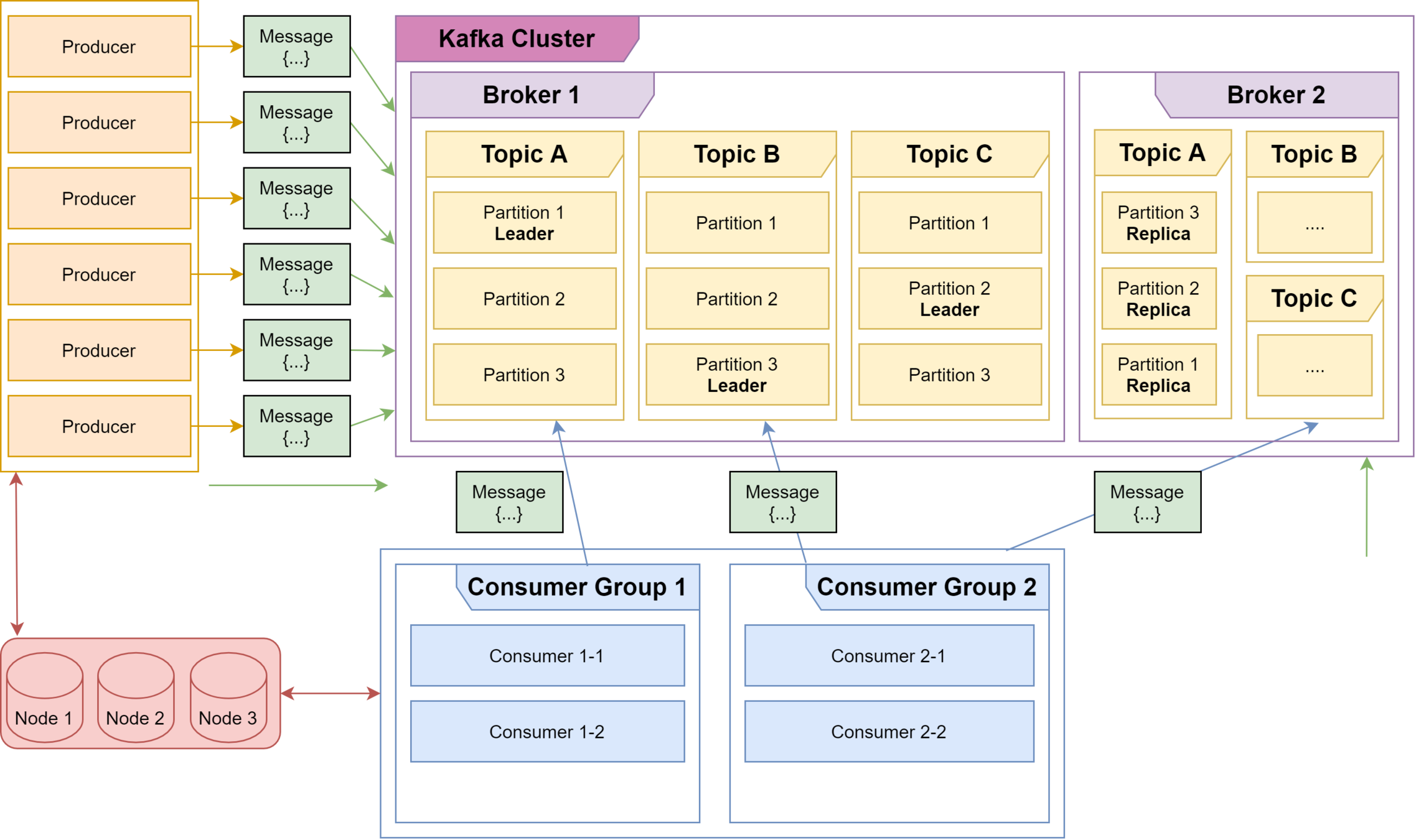
Overview of Kafka Architecture (Cont'd)

Multiple producers send messages to a Kafka Cluster, which is made of Kafka Brokers, each consisting of Topics and each Topic is a collection of Partitions.
The producer pushes a message to a topic's partition based on the record's key. If a key is missing, the partition is chosen using the round-robin method. Each topic has a leader partition.
Consumers pull records in parallel up to the number of partitions. The order guaranteed per partition only. If partitioning by key then all records for the key will be on the same partition which is useful if you ever have to replay the log.
Kafka can replicate partitions to multiple brokers for failover. Records in partitions are assigned sequential id number called the offset, which is the location inside that partition. This allows for multi-server scalability. Topic partitions are a unit of parallelism - a partition can only be worked on by one consumer in a consumer group at a time. Kafka has failover logic if a consumer dies, to reallocate to another consumer in the same consumer group.
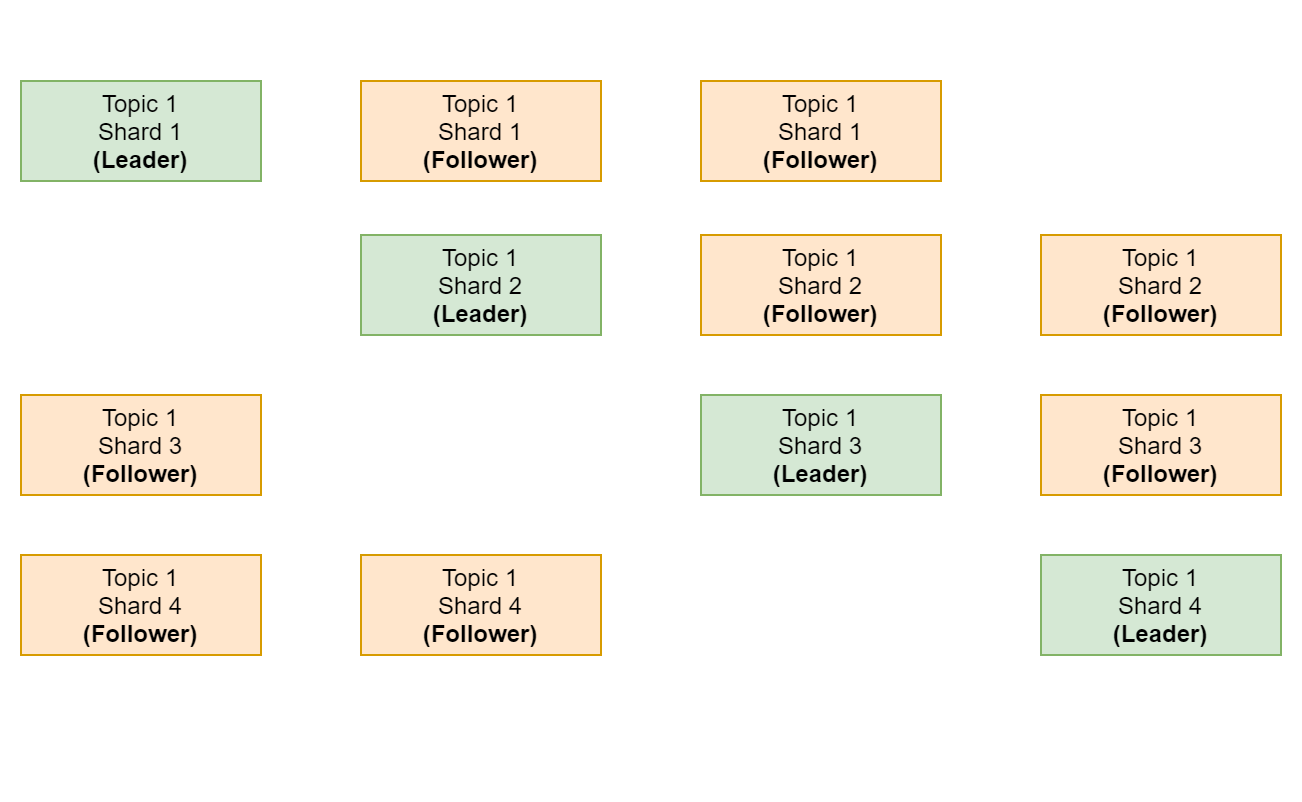
Leaders handle all read and write requests for a partition. A follower that is in-sync is called an ISR (in-sync replica). If a partition leader fails, Kafka chooses a new ISR as the new leader. SYNC replication, committed only when all replicas are in sync.
After a consumer reads a message, it commits the offset. (More on this in the next slide).
Apache Zookeeper is used to keep track of the committed offsets. It's also used to keep track of Broker IDs, for which producer to send to which Kafka broker, leader election, Access Control Lists & various other cluster configurations.
Consumer Mechanics
- Consumers remember the offset where they reached
- Each consumer group has its own offset per partition
- High watermark offset is the offset of the last message that was successfully copied to all of the log's replicas
- You can set custom message polling time

Producer Semantics

Since 0.11.0.0, the Kafka producer also supports an idempotent delivery option which guarantees that resending will not result in duplicate entries in the log. To achieve this, the broker assigns each producer an ID and deduplicates messages using a sequence number that is sent by the producer along with every message. Also beginning with 0.11.0.0, the producer supports the ability to send messages to multiple topic partitions using transaction-like semantics: i.e. either all messages are successfully written or none of them are. The main use case for this is exactly-once processing between Kafka topics.
-
At most once - Messages may be lost but are never redelivered.
(Can configure by disabling retries on the producer and committing offsets in the consumer prior to processing a batch of messages.) - At least once - Messages are never lost but may be redelivered. (Default behaviour)
- Exactly once - Each message is delivered once and only once.
Delivery type

- Strong guarantee - use synchronous commit, awaits commit to all replicas
- Can miss a message - send asynchronously or wait on commit only to leader
Options

Consumer Semantics

-
At-most-once (consumer failure) - Consumer reads the msg, saves the offset in the log and then processes the msg. If it crashes after reading and committing offset, but before sending the output from processing, other consumers would move on and the message would be ignored
-
At-least-once - Consumer reads the msg, processes it, commits the offset: it can crash after processing the msg, but before committing the offset. A new consumer takes over and processes the msg again. Better choice if your messages have primary key and updates are idempotent, and processing the same msg would yield the same result - replace the old data with new identical data.
- Exactly once case - Supported in Kafka Streams. The consumer's position is stored as a message in a topic, so we can write the offset to Kafka in the same transaction as the output topics receiving the processed data. If the transaction is aborted, the consumer's position will revert to its old value and the produced data on the output topics will not be visible to other consumers, depending on their "isolation level."
Do a 2-phase commit between the storage of the consumer position and the storage of the consumers output. This can be handled more simply by letting the consumer store its offset in the same place as its output. This is better because many of the output systems a consumer might want to write to will not support a two-phase commit.
External Systems

Log Compaction
Partition offsets are preserved and only the tail is compacted. Compaction doesn't block reads and can be throttled if needed to reduce performance impact. The Kafka Log Cleaner does log compaction. The Log cleaner has a pool of background compaction threads. These threads recopy log segment files, removing older records whose key reappears recently in the log. Each compaction thread chooses topic log that has the highest ratio of log head to log tail. Then the compaction thread recopies the log from start to end removing records whose keys occur later in the log.

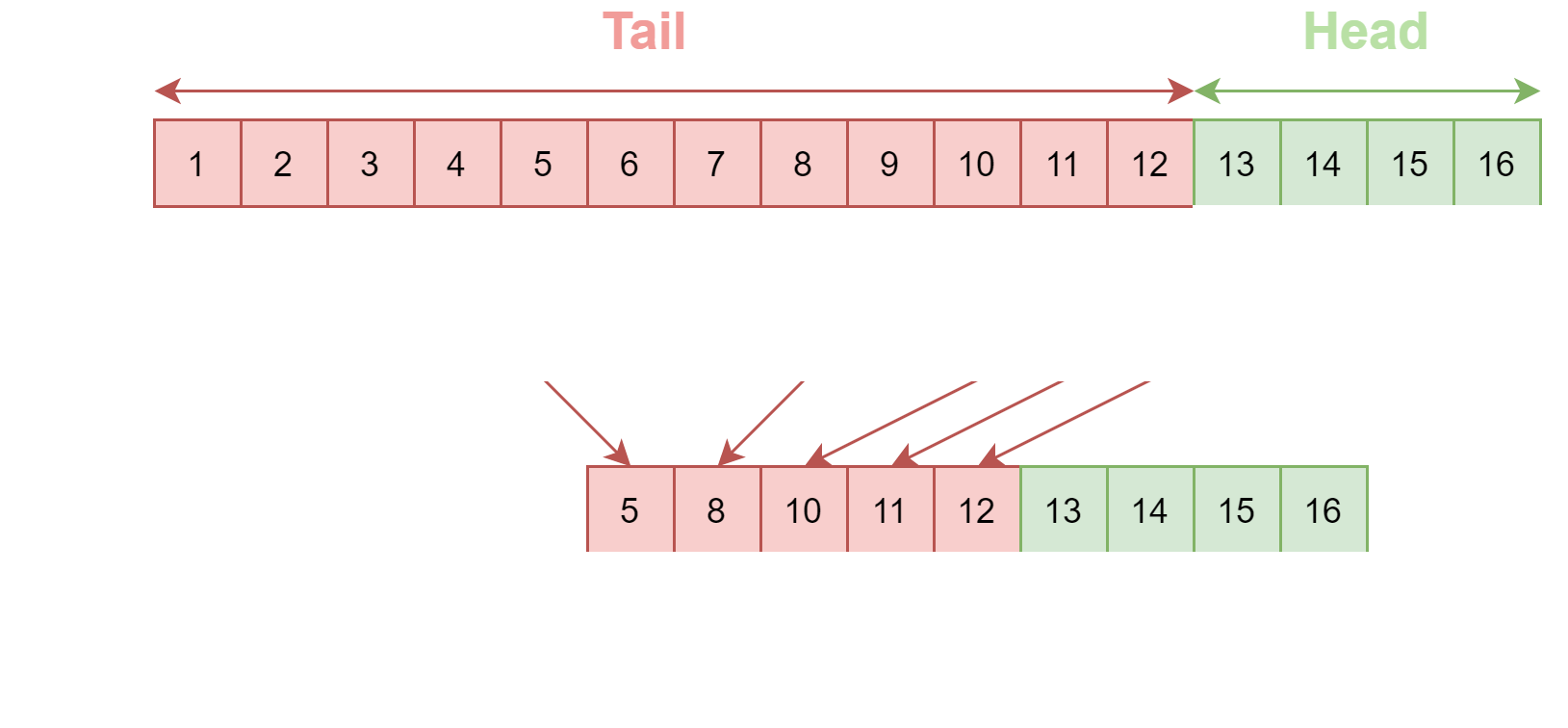
Why

Retains snapshot of latest values for all keys, useful to restore state after a crash, loss of connection or system failure for an in-memory service, a persistent data store or refreshing a cache.
How

As the log cleaner cleans log partition segments, the segments get swapped into the log partition immediately replacing the older segments (Inplace replace). This way compaction does not require double the space of the entire partition as additional disk space required is just one additional log partition segment - divide and conquer.
Internals

Replication

Kafka Streams & Kafka Connect
Kafka Streams
- API that allows for data transformation in real-time based on Kafka messages by publishing the transformation (statistics-based metrics for example) on to a new topic. The calculations happen inside your application, not on the Kafka Broker.
Kafka Connect
- API to define import/export pipeline for Kafka. End goal is standardization of common patterns and popular applications - like reading/writing to databases.



Sources

Thank you for listening!
